[ 2009-October-21 11:36 ]
Java provides two APIs for Network I/O: The original java.net.Socket class (via InputStream and OutputStream), and the newer java.nio.SocketChannel. Both of these eventually call the read and write operating system calls to actually send and receive data. However, I was curious about how exactly data gets to the operating system, since copying data multiple times is an easy way to decrease performance. I ended up spelunking through the Java source code to discover the answers. This article presents a brief walk through of the write path (the read path is basically identical), and some small benchmarks to discover the actual performance differences. The short summary is that NIO with direct ByteBuffers should be the most efficient form of I/O, but it depends on how your data gets into the buffers.
java.net.Socket
With the older Socket class, writes use SocketOutputStream. The write() method ends up invoking a JNI method, socketWrite0(). This function has a local stack allocated buffer of length MAX_BUFFER_LEN, which is set to 8192 in net_util_md.h). If the array fits in this buffer, it is copied using GetByteArrayRegion(). Finally, the implementation calls NET_Send, a wrapper around the send() system call. This means that every call to write a byte array in Java makes at least one copy that could be avoided in C. Even worse, if the Java byte array is longer than 8192 bytes, the code calls malloc() to allocate a buffer of up to 64 kB, then copies into that buffer. In other words, don't make calls to write() with arrays larger than 8 kB, since calling malloc() and free() for each write is probably bad.
java.nio.SocketChannel
With the newer NIO package, writes must use ByteBuffers. When writing, the data first ends up at sun.nio.ch.SocketChannelImpl. It acquires some locks then calls sun.nio.ch.IOUtil.write, which checks the type of ByteBuffer. If it is a heap buffer, a temporary direct ByteBuffer is allocated from a pool and the data is copied using ByteBuffer.put(). The direct ByteBuffer is eventually written by calling sun.nio.ch.FileDispatcherImpl.write0, a JNI method. The Unix implementation finally calls write() with the raw address from the direct ByteBuffer.
Microbenchmarks
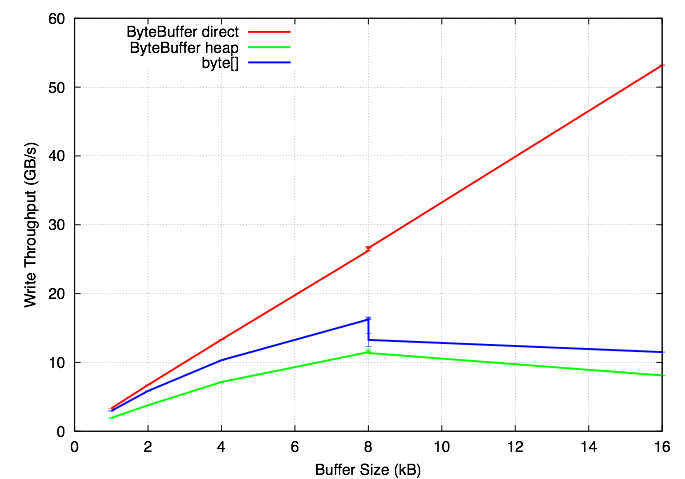
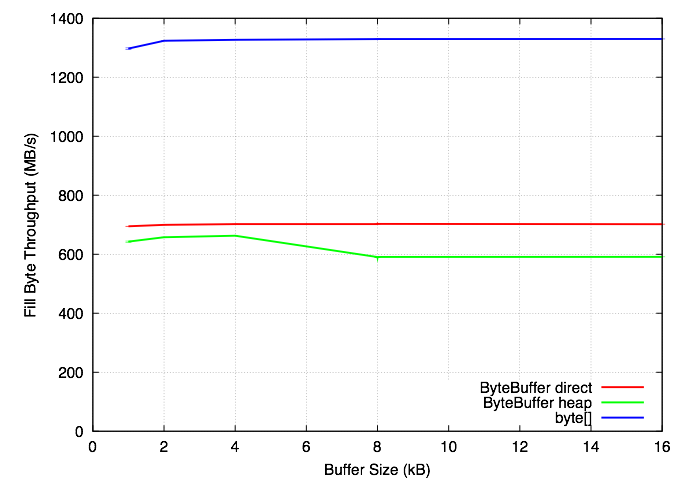
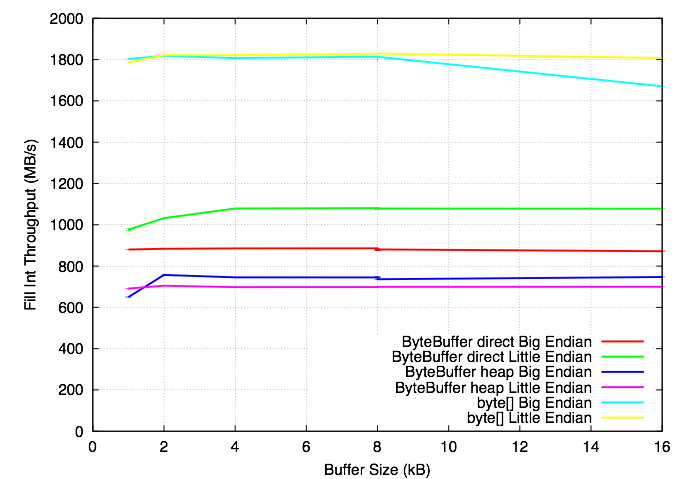
To quantify the performance differences, I wrote a small microbenchmark that compares byte[], direct ByteBuffers and heap ByteBuffers. The three tests are filling the buffers with integers, filling them one byte at a time, and writing them to /dev/null. When writing to /dev/null, the operating system does no work, so this should measure "best case" Java performance. I ran the tests on a 2.53 GHz Intel Xeon E5540 (Core i7/Nehalem architecture) Linux system, with Sun's Java 1.6.0_16. I also tried a JDK7 beta (1.7.0-ea-b74) and the results were the same, although jdk7's numbers were slightly better. The graphs below show the results, and the source code is linked at the bottom. The interesting observations:
OutputStream: When writing byte[] arrays larger than 8192 bytes, performance takes a hit. Read/write in chunks ≤ 8192 bytes.ByteBuffer: direct ByteBuffers are faster than heap buffers for filling with bytes and integers. However, array copies are faster with heap ByteBuffers (results not shown here). Allocation and deallocation is apparently more expensive for direct ByteBuffers as well.- Little endian or big endian: Doesn't matter for byte[], but little endian is faster for putting ints in ByteBuffers on a little endian machine.
- ByteBuffer versus byte[]: ByteBuffers are faster for I/O, but worse for filling with data.
Source code: javanetperf.tar.bz2 (includes previous benchmarks)
Conclusions
Direct ByteBuffers provide very efficient I/O, but getting data into and out of them is more expensive than byte[] arrays. Thus, the fastest choice is going to be application dependent. Amazingly, in my tests, if the buffer size is at least 2048 bytes, it is actually faster to fill a byte[] array, copy it into a direct ByteBuffer, then write that, then to write the byte[] array directly. However for small writes (512 bytes or less), writing the byte[] array using OutputStream is slightly faster. Generally, using NIO can be a performance win, particularly for large writes. You want to allocate a single direct ByteBuffer, and reuse it for all I/O to and from a particular channel. However, you should serialize and deserialize your data using byte[] arrays, since accessing individual elements from a ByteBuffer is slow.
Strangely, these results also seem to suggest that it could be faster to provide an implementation of FileOutputStream that is implemented on top of FileOutputChannel, rather than using the native code that it currently uses. It also seems like it may be possible to provide a JNI library for non-blocking I/O that uses byte[] arrays instead of ByteBuffers, which could be faster. While GetByteArrayElements always makes a copy (see DEFINE_GETSCALARARRAYELEMENTS in JDK7 jni.cpp), GetPrimitiveArrayCritical obtains a pointer, which could then be used for non-blocking I/O. This would trade the overhead of copying for the overhead of pinning/unpinning the garbage collector, so it is unclear if this will be faster, particularly for small writes. It also would introduce the pain of dealing with your own JNI code, and all the portability issues that come with it. However, if you have a very I/O intensive Java application, this could be worth investigating.
Related Links
- My previous comparison of the performance of NIO vs IO
- Direct versus heap ByteBuffer microbenchmark
- Channel versus InputStream microbenchmark
- byte[] versus ByteBuffer performance
- ByteBuffer performance discussion about JDK 1.4
Detailed Performance Results